pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple mkdocs
控制台输出文字颜色改变
# 36是颜色号,从32-38选个颜色,后面部分是结束的意思,不然后面文字输出的颜色也会改变
print('\033[36m' + banner + '\033[0m')
格式化输出:%,format(),f
%:使用
- %s 字符串
- %d 整数
- %f 浮点数
name = 'bill'
age = 30
salary = 300000.01
print('my name is %s .'%name)
print('my age is %d .'%age)
print('my salary is %.2f .'%salary) # 浮点数可以设置保留几位小数位
print('My name is %s , my age is %d , my salary is %.4f .' %(name, age, salary))
format():使用
name = 'bill'
age = 30
salary = 300000.01
# 一个占位符
print('my name is {} .'.format(name))
# 多个占位符,可以指定参数位置
print('My name is {1} , my age is {0} '.format(age, name))
# 多个占位符,根据变量指定参数位置
print('My name is {x} , my age is {y} , my salary is {z} .'.format(x = name, y = age, z = salary))
f:使用
name = 'bill'
age = 30
salary = 300000.01
# 一个占位符
print(f'my name is {name} .')
# 多个占位符
print(f'My name is {name} , my age is {age} .')
string 编码:encode 与 decode
https://www.cnblogs.com/ugvibib/p/14991986.html
文件操作:with open
模式
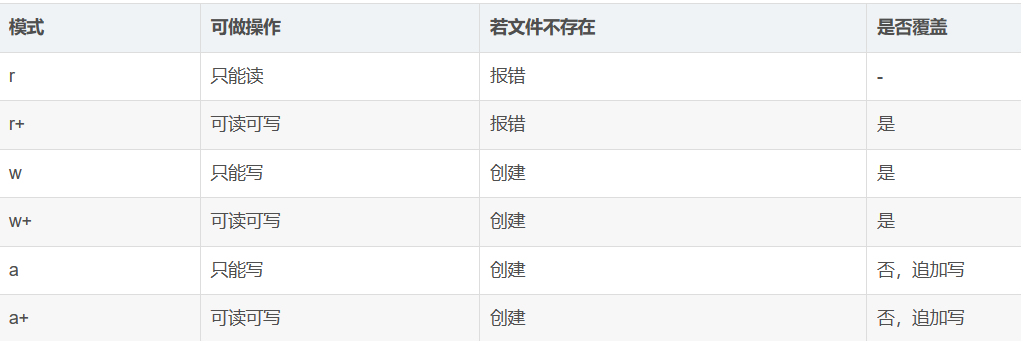
with open("./backup/1.txt","w") as f:
f.write("hello")
命令行参数
sys 模块
虚拟环境:venv
使用 powershell 运行以下命令
先更新一下 pip:python.exe -m pip install --upgrade pip
python -m venv myvenv # 创建一个名为myvenv的虚拟环境,删除的话直接删除文件夹即可
.\.venv\Scripts\Activate.ps1 # windows启动这个环境,启动后前面有一个标识
source ./test_env/bin/activate # linux或Mac
deactivate # 退出虚拟环境
问题
激活虚拟环境 powershell 报错:问题的根源在于 win 10 默认的执行策略是不载入任何配置文件,不运行任何脚本。
输入以下命令:Set-ExecutionPolicy -Scope CurrentUser RemoteSigned
参考: https://zhuanlan.zhihu.com/p/484073745
字符串操作
字符串的转换
lower ():字符串中所有字母转小写字母,支持英文字母
upper ():字符串中所有字母转大写字母
str1 = "Ahello,AfunD"
print(str1.lower())
print(str1.upper())
======输出============
ahello,afund
AHELLO,AFUND
casefold (): 方法返回一个字符串,其中所有字符均为小写。多语种
此方法与 Lower () 方法相似,但是 casefold () 方法更强大,更具攻击性,这意味着它将更多字符转换为小写字母,并且在比较两个用 casefold () 方法转换的字符串时会找到更多匹配项。
swapcase ():大小写互换
str1 = "Ahello,AfunD"
print(str1.swapcase()) # aHELLO,aFUNd
capitalize ():首字母大写
str = "hello,tom.hello"
print(str.capitalize())
=====输出===============
Hello,tom.hello
title ():字符串中每个单词首字母大写,其余字母小写(区分单词以空格区分)
str = "Hello tom.hello"
print(str.title())
=====输出===============
Hello Tom.Hello
字符串的替换
replace (old_str, new_str, num):使用新字符串,替换原始字符串中的指定字符串信息
old_str: 被替换的字符串
new_str: 新字符串
num:替换数量
str1 = "Ahello,Anihao"
print(str1.replace("A", "a"))
print(str1.replace("A", "a", 1))
=====输出===========================
ahello,anihao
ahello,Anihao
expandtabs ():使用空格替换原始字符串中的制表位\t
# 暂无
字符串的删除
strip (str):去掉字符串左右两侧在参数字符串中包含的所有字符
lstrip (str):去掉字符串左侧在参数字符串中包含的所有字符
str1 = "Ahello,AfunDA"
print(str1.strip("A"))
print(str1.lstrip("A"))
=======输出=================
hello,AfunD
hello,AfunDA
ljust
rjust
center
zfill
字符串的判断
islower ():判断是否全为小写
isupper ():判断是否全为大写
str1 = "Hello tom.hello"
str2 = "hello"
str3 = "HELLO"
print(str1.islower())
print(str2.islower())
print(str3.islower())
print(str3.isupper())
=====输出=============
False
True
False
True
startswith ():判断字符串是否以指定字符串开始
endswith ():判断字符串是否以指定字符串结束
str1 = "Hello tom.hello1"
print(str1.startswith("Hello"))
print(str1.endswith("llo1"))
=====输出========================
True
True
字符串的查找
注:字符串下标从 0 开始
find (str, begin, end):从左侧查找字符串从指定开始位置到指定结束位置间第一次出现的索引位置
str:要查找的字符串
begin:开始索引,整数,该值要小于 end,否则结果为-1
end:结束索引,整数,该值要大于 begin,否则结果为-1
str1 = "Hello tom.hello"
print(str1.find("t")) # 输出:6
print(str1.find("t", 6, 7)) # 输出:6
print(str1.find("t", 6, 6)) # 输出:-1
print(str1.find("t", 3, 6)) # 输出:-1
rfind (str, begin, end):从右侧查找
str1 = "Hello tom.hello"
print(str1.find("o"))
print(str1.rfind("o"))
=====输出================
4
14
index (str, begin, end):如果包含子字符串,返回开始的索引值,否则抛出异常。
str1 = "Hello tom.hello"
print(str1.index("tom")) # 输出:6
print(str1.index("tom2")) # 报异常:ValueError: substring not found
count ():计算一个词的出现次数
str = "Hello,tom.hello" # 注意大小写
print(str.count("h"))
======输出===============
1
字符串的拼接
join ():将原始字符串填充到参数的每个字符之间组成新的字符串返回(占位连接)
str2 = "666"
str3 = "a#a"
print(str3.join(str2))
======输出==============
6a#a6a#a6
+:多个字符串拼接在一起
str2 = "666"
str3 = "a#a"
print(str2 + str3)
=====输出=============
666a#a
字符串的拆分
split ():使用参数作为分割线,将原始字符串拆分成若干个字符串,并组织成列表返回
str1 = "Hello tom.hello"
print(str1.split(".")) # 参数本身不返回,列表中没有它
print(str1.split(".")[0])
print(str1.split("o"))
print(str1.split("o")[-2])
======输出==================
['Hello tom', 'hello']
Hello tom
['Hell', ' t', 'm.hell', '']
m.hell
partition ():从左边开始分割
rpartition ():从右边开始分割
str1 = "Hello tom.hello"
print(str1.partition("tom"))
print(str1.partition("tom")[1])
print(str1.rpartition("tom"))
print(str1.rpartition("tom")[1])
print("他两有什么不同呢?")
print(str1.partition("j"))
print(str1.rpartition("j"))
=========输出=====================
('Hello ', 'tom', '.hello')
tom
('Hello ', 'tom', '.hello')
tom
他两有什么不同呢?
('Hello tom.hello', '', '')
('', '', 'Hello tom.hello')
splitlines ():以换行符作为分割
str1 = "Hello \ntom.he\nllo"
print(str1)
print("以换行符作为分割")
print(str1.splitlines())
=====输出====================
Hello
tom.he
llo
以换行符作为分割
['Hello ', 'tom.he', 'llo']
python 常用库
json 库的使用
dumps 是将 dict 转化成 str 格式,loads 是将 str 转化成 dict 格式。
dump 和 load 也是类似的功能,只是与文件操作结合起来了。
| 函数 | 描述 |
|---|---|
| json. dumps | 将 Python 对象编码成 JSON 字符串 |
| json. loads | 将已编码的 JSON 字符串解码为 Python 对象 |
| json. dump | 将 Python 对象写入 json 文件 |
| json. load | 从一个文件读取 JSON 类型的数据,然后转换成 Python 对象 |
1、dumps 和 loads
将对象和 json 相互转换
ensure_ascii=False:保证 dumps/dump 之后的结果里所有的字符都能够被 ascii 表示
import json
data = {'name': '张三', 'age': 25}
print(type(data))
# 将对象转为json字符串
json_data = json.dumps(data, ensure_ascii=False)
print(json_data)
print(type(json_data))
print("------------------------")
# 将json字符串转为对象
l_data = json.loads(json_data)
print(l_data)
print(type(l_data))
=========输出=============
<class 'dict'>
{"name": "张三", "age": 25}
<class 'str'>
------------------------
{'name': '张三', 'age': 25}
<class 'dict'>
2、dump 和 load(文件)
dump 和 load,只是与文件操作结合起来了
import json
dictionary = {
"id": "04",
"name": "sunil",
"clsaaname": "一班"
}
with open("D:/1.txt", "w")as f:
json.dump(dictionary, f, ensure_ascii=False)
读取 json 文件,转为对象
import json
with open("D:/1.txt", "r") as f:
read_data = json.load(f)
print(read_data)
print(type(read_data))
====输出==================================
{'id': '04', 'name': 'sunil', 'clsaaname': '一班'}
<class 'dict'>
base 64 库的使用
base 64 编码:
首先将字符串(图片等)转换成二进制序列,然后按每 6 个二进制位为一组,分成若干组,如果不足 6 位,则低位补 0。每 6 位组成一个新的字节,高位补 00,构成一个新的二进制序列,最后根据 base 64 索引表中的值找到对应的字符。
注意:在 base 64 编码中,中文使用 GBK 编码和 UTF-8 编码得到的结果是不同的
base 64 模块真正用的上的方法只有 8 个,分别是 encode, decode, encodestring, decodestring, b 64 encode, b 64 decode, urlsafe_b 64 decode, urlsafe_b 64 encode。
encode, decode:专门用来编码和解码文件的, 也可以 StringIO 里的数据做编解码;
encodestring, decodestring:专门用来编码和解码字符串;
b 64 encode 和 b 64 decode:用来编码和解码字符串,并且有一个替换符号字符的功能;
urlsafe_b 64 encode 和 urlsafe_b 64 decode:这个就是用来专门对 url 进行 base 64 编解码的。
对字符串进行编码和解码操作
import base 64
# 对于中文,不同的编码,结果不同
stru = "hello 你好".encode ("utf-8")
strg = "hello 你好".encode ("GBK")
str 1 = base 64.b 64 encode (stru)
str 2 = base 64.b 64 encode (strg)
print (str 1.decode ("utf-8"))
print (str 2.decode ("GBK"))
print (base 64.b 64 decode (str 1).decode ("UTF-8"))
print (base 64.b 64 decode (str 2).decode ("gbk"))
=====输出=============================
aGVsbG/kvaDlpb 0=
aGVsbG/E 47 rD
hello 你好
hello 你好
注意:编码和解码操作的都是 byte 类型,所以要先对字符串进行编码转换
# 这样是错误的
str = "hhh 你"
print (base 64.b 64 encode (str))
====输出========================
TypeError: a bytes-like object is required, not 'str'
os 库
系统操作接口
os. name:获取当前 Python 运行所在的环境
import os
print(os.name)
# 返回:posix(Linux) nt(Windows)
os. system:获取程序执行命令的返回值。如果执行成功,那么会返回 0,表示命令执行成功。否则,则是执行错误。
import os
os.system("apt update")
print(res) # 0
os. popen:获取程序执行命令的输出结果
import os
res = os.popen("apt-get update") # 返回一个文件对象
print(res.read()) # 对文件对象进行读操作
res.close() # 文件对象,尽量关闭
非阻塞式,即命令不会从上往下依次等待执行,可能上一个命令没执行完,下一个命令就执行完毕了。那如何让命令执行完后,再执行下一句呢?处理方法是使用 read () 或 readlines () 对命令的执行结果进行读操作。
os.mkdir:以数字权限模式创建目录(单级目录)。默认的模式为 0777 (八进制)
os.makedirs:递归创建目录
path 子模块
os. path. exists ():判断路径所指向的位置是否存在。若存在则返回 True,不存在则返回 False
print (os.path.exists ("D:/1.txt"))
=====输出==========================
True
os. path. isfile () 和 os. path. isdir ()
print (os.path.isfile ("D:/1.txt"))
=====输出=========================
True
requests 库
发起请求
requests.get(url=target_url,headers=headers,params=params)
requests.post(url=target_url, headers=headers, data=data)
参数详解
核心参数
url: 请求的目标 URL(必需)params: 附加到 URL 的查询参数(字典或字节)headers: 自定义请求头(字典)data:发送请求体(Body)数据,常用于 POST、PUT、PATCH 等需要提交数据的请求。
其他常用参数
timeout: 超时时间(秒)proxies: 代理服务器设置(字典)verify: SSL 证书验证(布尔值或证书路径)auth: 身份认证(元组)cookies: 附加 Cookie(字典或 CookieJar)allow_redirects: 是否允许重定向(布尔值)stream: 流式传输开关(布尔值)
示例
import requests
response = requests.get(
"https://api.example.com/data",
params={"page": 2},
headers={"User-Agent": "MyApp"},
timeout=5
)
data 和 params 区别
1.用途不同
- params → 构造URL的查询参数(?key=value形式)
- data → 发送HTTP请求体(Body)中的数据
2.适用方法
- params → 主要用于GET请求
- data → 主要用于POST/PUT/PATCH请求
3.数据位置
- params → 附加在URL末尾(明文可见)
- data → 隐藏在请求体中(HTTPS下加密)
4.编码方式
- params → 自动进行URL编码(如空格 → %20)
- data → 默认按表单格式编码(x-www-form-urlencoded)
5.敏感数据处理
- params → 不适合传递密码等敏感信息(暴露在URL)
- data → 更安全(配合HTTPS使用)
6.混合使用场景
- 可同时用于同一请求(如POST请求):
requests.post(url,params={"page":1},data={"user":"admin"})
7.常见误区
- GET + data → 服务器可能忽略 Body 数据
- JSON 数据 → 应使用 json 参数而非 data
结果处理
resp. text 返回的是 Unicode 型的数据。
resp. content 返回的是 bytes 型也就是二进制的数据。
代理设置
1)使用 proxies 参数设置全局代理
import requests
url = "http://192.168.31.211"
params = {"username": "root", "password": "passwd"}
proxies = {
"http": "http://127.0.0.1:8080",
"https": "http://127.0.0.1:8080"
}
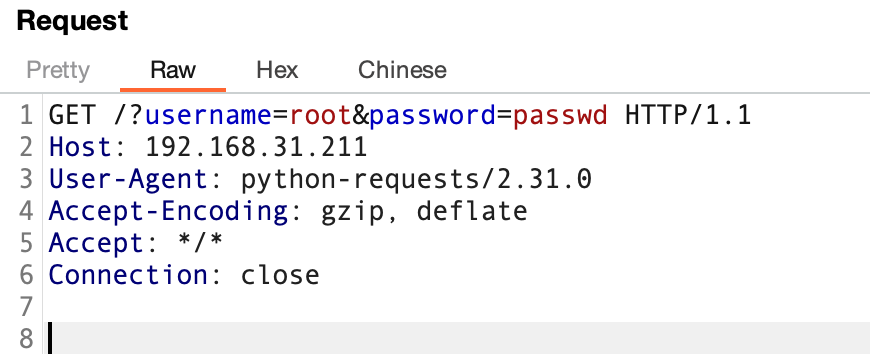
r1 = requests.get(url=url, params=params,proxies=proxies)
print(r1.url)
###### 输 出 ################
http://192.168.31.211/?username=root&password=passwd
burpsuite 设置好后可以抓到包
post 请求代理
import requests
url = "http://192.168.31.211"
data1 = "username=root&password=passwd"
proxies = {
"http": "http://127.0.0.1:8081"
}
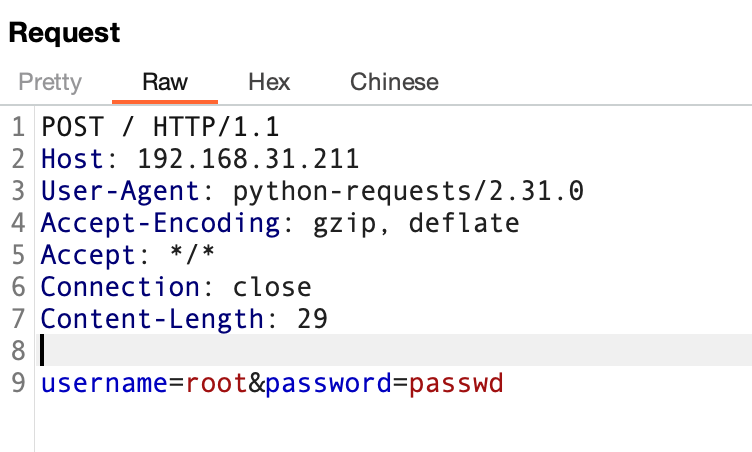
r2 = requests.post(url=url, data=data1,proxies=proxies)
print(r2.url)
###### 输出 #######
http://192.168.31.211/
burp 抓到的数据包
2)使用 session 对象设置会话级别的代理
argparse 库
位置参数和可选参数:在命令行中传入参数时候,传入的参数的先后顺序不同,运行结果往往会不同,这是因为采用了位置参数;为了在命令行中避免上述位置参数的 bug(容易忘了顺序),可以使用可选参数,这个有点像关键词传参,但是需要在关键词前面加 --
长选项字符串和短选项字符串
在使用 argparse 模块处理命令行参数时,“-” 和 “--” 是用来表示不同类型的参数的前缀。
“-”(单破折号)通常用于表示单字符的命令行选项,也称为短选项。短选项通常用于表示简单的开关或标志。例如,“-v” 可以表示启用详细输出。
“--”(双破折号)通常用于表示完整的命令行选项,也称为长选项。长选项通常用于提供更具描述性的选项名称和更丰富的配置选项。例如,“--verbose” 可以表示启用详细输出。
使用短选项时,可以将多个短选项连接在一起。例如,“-abc” 可以表示启用选项 a、b 和 c。
使用长选项时,通常使用等号(=)将选项与其值分隔开。例如,“--output=file.txt” 可以表示将输出写入 file.txt 文件。
总结起来:
短选项(单破折号)通常是单字符的,用于简单的开关或标志。
长选项(双破折号)通常是完整的单词,用于提供更具描述性的选项名称和更丰富的配置选项。
在使用 argparse 模块时,可以根据需要选择适合的选项风格来解析和处理命令行参数。
这里有一个约定俗成的惯例:单个字母只是用一个-,多个字母使用--。python也支持一个-后面跟多个字母,不过看起来有关怪异。
(1)import argparse 首先导入模块
(2)parser = argparse.ArgumentParser() 创建一个解析对象
(3)parser.add_argument() 向该对象中添加你要关注的命令行参数和选项
(4)parser.parse_args() 进行解析
# 创建一个解析对象
parser = argparse.ArgumentParser(usage="这是usage",description="这是一个测试用例")
# usage:描述程序用法的字符串(默认值:从添加到解析器的参数生成)
# description:简要描述这个程序做什么以及怎么做。要在参数帮助信息之前显示的文本(默认:无文本)
# 其它参数:https://docs.python.org/zh-cn/3/library/argparse.html#argparse.ArgumentParser
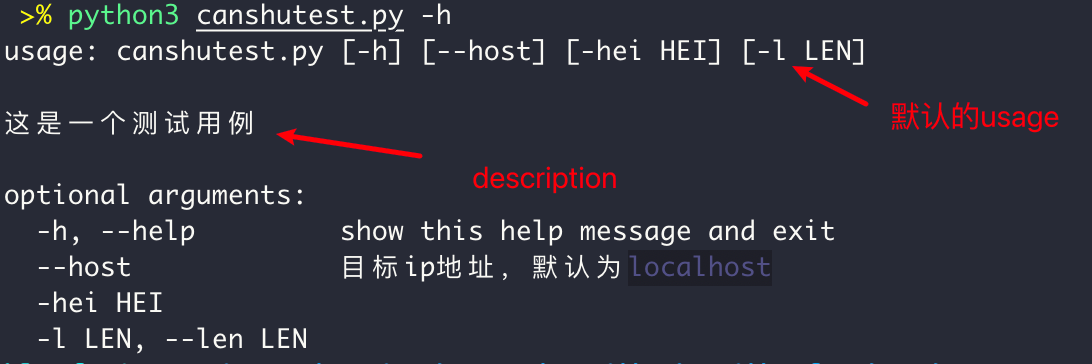
修改后的 usage 参数
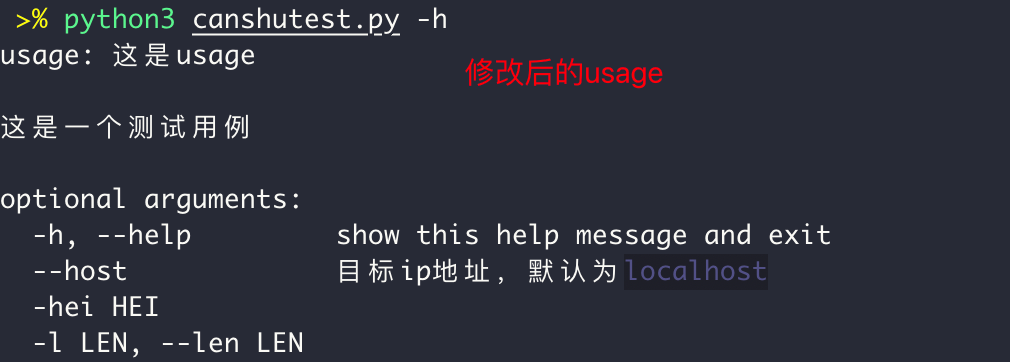
parser.add_argument('--host', dest='', default='localhost',required=True,help='目标ip地址,默认为localhost')
# 参数选项
# dest:自定义属性名称,需要用到这个来获取参数的值,以便进行下一步处理
# default:参数的默认值
# help:显示帮助信息
# type:命令行参数应当被转换成的类型。
# metavar:-h时显示在参数旁边,就是使用的参数值示例,默认使用dest的值。位置参数,直接使用dest值,可选参数,使用dest值的大写
# required:参数必选,没有运行报错提示。required=True
# action:令行参数应当如何处理
# 详细说明参考:https://docs.python.org/zh-cn/3/library/argparse.html#the-add-argument-method
例如:
parser.add_argument('-l', '--len', type=str, default='77')
parser.add_argument('-u', metavar='username', default='name')
parser.add_argument('-p', metavar='password', default='passwd')
parser.add_argument('--host1', dest='host11111', default='localhost',help='目标ip地址,默认为localhost')
parser.add_argument('--host2', dest='host2',metavar='metavar_host', default='localhost')
args = parser.parse_args()
# 获取参数值,是根据dest参数的值获取,dest的值默认:有长参数的话去掉 -- 的小写;没有长参数,用短参数去掉 - 的小写
# metavar默认使用dest的值
print(args.u) # 短参数,dest值为 u
print(args.p)
print(args.host11111) # 指定dest值
print(args.len) # 有长参数,dest值为len
##########运行并输出##########
>% python3 test.py -l 55
name
passwd
localhost
55
例子演示
import argparse
# 创建一个解析对象
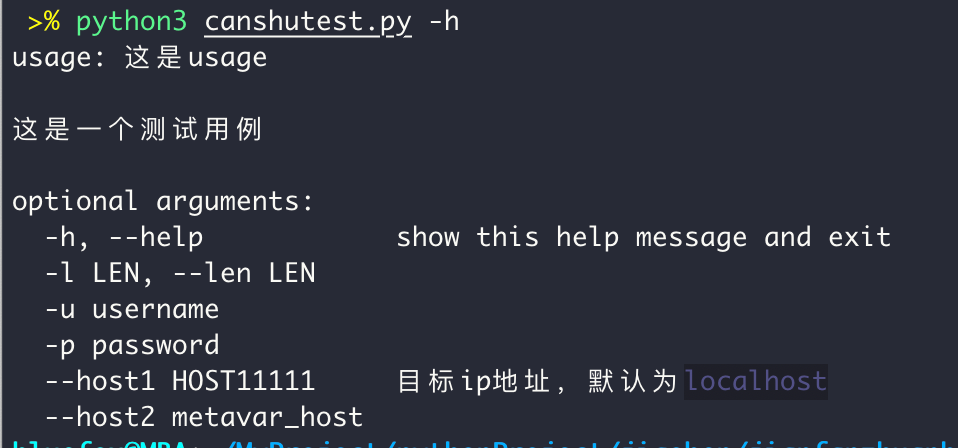
parser = argparse.ArgumentParser(description="这是一个测试用例",usage="这是usage")
# 向该对象中添加你要关注的命令行参数和选项
parser.add_argument('-l', '--len', type=str, default='77')
parser.add_argument('-u', metavar='username', default='name')
parser.add_argument('-p', metavar='password', default='passwd')
parser.add_argument('--host1', dest='host11111', default='localhost',help='目标ip地址,默认为localhost')
parser.add_argument('--host2', dest='host2',metavar='metavar_host', default='localhost')
# 进行解析
args = parser.parse_args()
# 获取参数的值
print(args.u)
print(args.p)
print(args.host11111)
print(args.len)
输出帮助信息
web
web. py 是一个 python 的 Web 框架,既简单又强大
https://github.com/webpy/webpy
安装命令
pip install web.py==0.62
telnetlib
telnetlib 模块提供一个实现Telnet协议的类 Telnet。官方文档
建立连接有两种方式:
- 实例化函数的时候,将可选参数 host 和 port 传递给构造函数,在这种情况下,到服务器的连接将在构造函数返回前建立。
- 使用telnetlib.Telnet类的open函数建立连接。
import telnetlib
HOST = "10.102.1.12"
#方式1
tn = telnetlib.Telnet(HOST, port=21, timeout=10) # 实际上也是在初始化时,调用了open方法
#方式2
tn = telnetlib.Telnet()
tn.open(HOST, port=21)
smtplib :邮件发送
参考: https://www.cnblogs.com/testlearn/p/14548396.html
方法
smtplib.SMTP_SSL(host, port,...):创建 SMTP 对象。
所有的参数都是可选的。创建 SMTP 对象的时候提供了(host, port)这两个参数,在初始化的时候会自动调用 connect 方法去连接服务器 smtplib 模块还提供了 SMTP_SSL 类和 LMTP 类,对它们的操作与 SMTP 基本一致
SMTP.connect([host[, port]]):连接到指定的 smtp 服务器。参数分别表示 smpt 主机和端口。
SMTP.login(user, password):登陆到 smtp 服务器。现在几乎所有的 smtp 服务器,都必须在验证用户信息合法之后才允许发送邮件。
SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options]) :发送邮件。这里要注意一下第三个参数,msg 是字符串,表示邮件。我们知道邮件一般由标题,发信人,收件人,邮件内容,附件等构成,发送邮件的时候,要注意 msg 的格式。这个格式就是 smtp 协议中定义的格式。(sendmail 函数,需要结合 email 模块的内容,一起使用)
SMTP.quit():断开与 smtp 服务器的连接
例子:使用第三方邮箱(QQ 邮箱)发送邮件。
import smtplib
# 1.连接邮件服务器
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
# 2.登录服务
server.login("admin@qq.com", "xxxxxxxxxx") # 括号中对应的是发件人邮箱账号、邮箱密码(一般是授权码)
# 3.构造邮件内容
mailbox_container = MIMEText('Hello Python!', "plain", "utf-8") # 创建文本类型容器
mailbox_container["From"] = "admin <admin@qq.com>" # 发件人的描述,QQ邮箱必须有
mailbox_container["subject"] = Header("我是主题信息","utf-8") # 邮件主题
# 4.发送邮件,可以发送多个联系人
server.sendmail("admin@qq.com", ["send666@qq.com"], mailbox_container.as_string())
# 5.关闭连接
server.quit()
问题
问题:QQ邮箱使用SMTPLIB 报错550,‘The “From” header is missing or invalid.原因以及解决办法
mailbox_container["From"] 必须有这个,使用QQ邮箱的时候,请务必按照 昵称+空格+<邮箱地址>形式:nickname <prefix@domain>声明 From Header。否则即使删除 utf-8,其报错依旧
其次,删除 From Header 中的 utf-8 字符串,或者不声明`From Header`为utf-8格式即可。
参考:https://blog.csdn.net/qq_41158337/article/details/130193810
一封 Email 邮件,不仅仅是有一些字符串组成的内容,它是一个结构,有收件人,发件人,抄送名单,邮件主题等等。而组织 Email 邮件内容结构的任务,不属于 smtplib 模块范围,我们需要用到 email 模块(标准库中的模块)提供的一些工具。
from email.header import Header # 用来对Email标题进行编码
from email.mime.text import MIMEText # 负责构造文本
from email.mime.image import MIMEImage # 负责构造图片
from email.mine.multiprt import MIMEMultipart # 负责将多个对象集合起来
from email.mime.base import MIMEBase # 添加附件的时候用到
from email.utils import parseaddr, formataddr
参考: https://cloud.tencent.com/developer/article/1853286
1)发送文本
MIMEText(text, subtype, charset)
- text:邮件正文内容,可以是纯文本或 HTML 格式
- subtype:邮件正文内容的类型,可以是"plain"(纯文本)、“html”(HTML 格式)
- charset:邮件正文内容的编码方式,常用的有"utf-8"、"gbk"等
例子:
from email.mime.text import MIMEText
# ----------方法1
msg = MIMEText('测试邮件。收到请不用回复', 'plain', 'utf-8')
# -----------方法2
content = '''
<p>我的地址:</p>
<p><a href='http://hldaig.xyz/'>点击进入我的</a></p>
<p>我的公众号二维码:</p>
<p><img src="cid:image"></p>
'''
html = MIMEText(content, 'html', 'utf-8')
2)其它类型: https://blog.csdn.net/qq_53937294/article/details/133177305
paramiko
参考: https://www.cnblogs.com/wongbingming/articles/12384764.html
用来进行 ssh 远程登录的模块。有两种登录方式:sshclient 和 transport 方式。
sshclient 是传统的连接服务器、执行命令、关闭的一个操作,多个操作需要连接多次,无法复用连接。有时候需要登录上服务器执行多个操作,比如执行命令、上传/下载文件,那就可以使用 transport 的方法。(推荐使用 transport)
使用 transport 方式登录
import paramiko
import time
# 1.建立连接
trans = paramiko.Transport(("192.168.195.233", 22))
trans.connect(username="root", password="root123")
# 2.将sshclient的对象的transport指定为以上的trans
ssh = paramiko.SSHClient()
ssh._transport = trans
# 3.允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 4.执行多条命令,返回结果
ssh_stdin, ssh_stdout, ssh_stderr = ssh.exec_command("pwd;ls -la;ps -aux",get_pty=True)
time.sleep(2)
print(ssh_stdout.read().decode())
# 5.关闭连接
trans.close()
exec_command()方法详解
- 调用 exec_command 时,Paramiko 会在服务器上打开一个新的通道(Channel),并执行提供的命令。该方法返回三个文件类对象,分别对应于命令的标准输入、标准输出和标准错误流。这些对象可以用来读取命令的输出或向命令发送输入。
- exec_command 方法不支持交互式命令或需要持续环境的命令。每次调用 exec_command 都会在一个新的环境中执行命令,之前的状态不会保留。
- 如果需要执行需要交互或持续环境的命令,可以使用 invoke_shell 方法,它提供了一个类似于终端的接口。
注意:执行多条命令时,需要添加 get_pty=True 参数(get_pty(bool 类型):实际在远程执行 sudo 命令时,一般主机都会需要通过 tty 才能执行,通过把 get_pty 值设置为 True,可以模拟 tty)
报错
1)AttributeError: 'NoneType' object has no attribute 'time'
模块有 bug 导致
解决方法:执行命令后运行 time.sleep(2) 或者关闭ssh_stdin.close()
pip 命令
python2 是使用 pip,python3 是使用 pip3。如果只安装了 python3,那么 pip 和 pip3 都行,如果同时有 python2 和 python3,那么使用 pip 则是用的 python2。
1、pip 换源
临时换源
#清华源
pip install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip install markdown -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# 腾讯源
pip install markdown -i http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip install markdown -i http://pypi.douban.com/simple/
永久换源
找到 ~/.pip/pip.conf,在文件中添加或修改(没有就创建一个)
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
2、pip 常用命令
# debian 安装pip
apt install python3-pip # 安装Python3的pip
apt install python-pip # 安装Python2的pip
# centos 安装pip
yum install python-pip # for Python2
yum install python3-pip # for Python3
# pip常用命令(python3环境)
pip3 -version # 查看 pip 版本
pip list # 列出已安装的包
pip3 install SomePackage # 安装包的最新版本
pip3 install SomePackage==1.0.4 # 指定版本
pip3 install SomePackage>=1.0.4 # 最小版本
pip3 install SomePackage>=1.0,<=1.5
pip3 search SomePackage # 搜索安装包,这样搜索报错,下方有解决方法
pip3 show SomePackage # 显示已安装包信息
pip3 show -f SomePackage # 显示已安装包的详细信息
pip3 uninstall SomePackage # 卸载包
# 查看历史版本。报错,新版本才有这个命令。或直接到 https://pypi.org/ 搜包名查找
pip3 index versions SomePackage
# 更新已安装的包
pip list --outdated # 查看所有可更新的模块
pip install --upgrade SomePackage # 更新某一个包
# 升级pip.非必要勿升级
python3 -m pip install --upgrade pip
3、使用问题
1)搜索报错
ERROR: XMLRPC request failed [code: -32500]
RuntimeError: PyPI no longer supports 'pip search' (or XML-RPC search). Please use https://pypi.org/search (via a browser) instead. See https://warehouse.pypa.io/api-reference/xml-rpc.html#deprecated-methods for more information
因为 pip search 服务的请求量激增,而开发新的搜索方式需要投入大量的人力物力,所以官方永久禁用 XMLRPC 搜索功能
解决方式
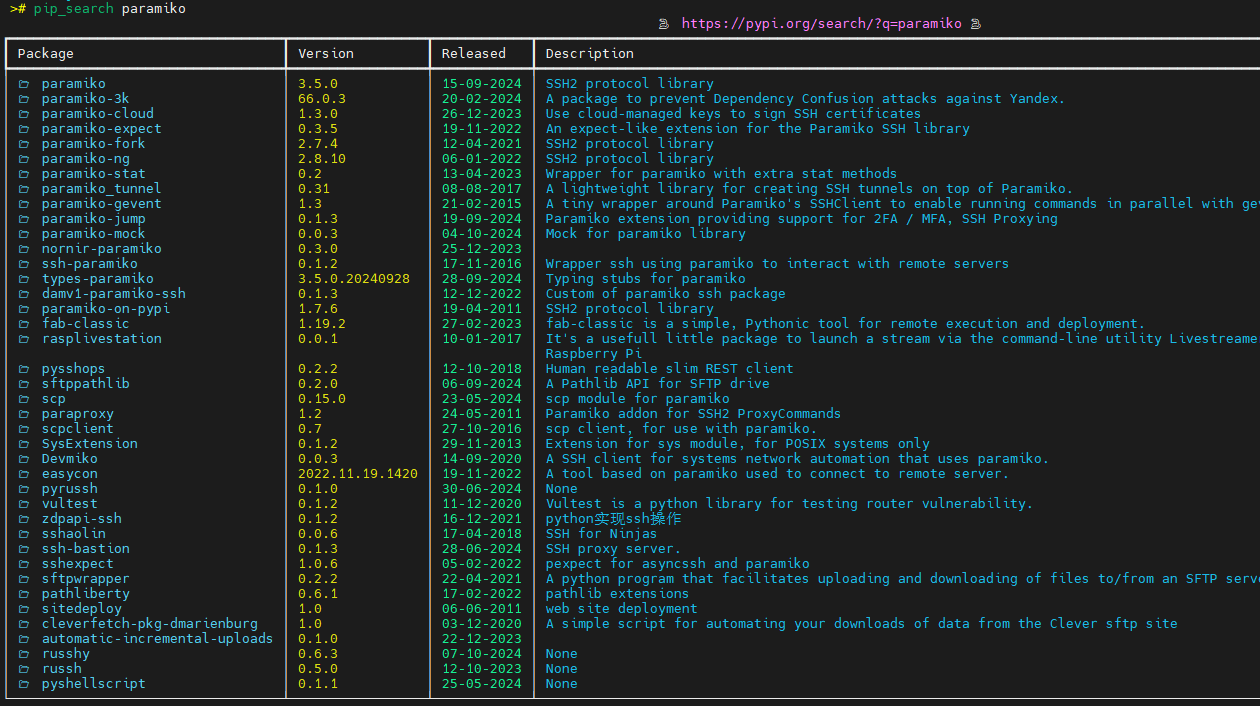
用 pip-search 代替,安装: pip3 install pip-search
例如:pip_search paramiko
time 模块
# 获取当前时间戳,浮点数
print(time.time()) # 1728729714.0869093
# 推迟调用线程的运行,单位:秒。可以是小数
time.sleep(2)
# 格式化时间戳为本地的时间
print(time.localtime()) # time.struct_time(tm_year=2024, tm_mon=10, tm_mday=12, tm_hour=18, tm_min=41, tm_sec=56, tm_wday=5, tm_yday=286, tm_isdst=0)
# 格式化时间,若未输入参数,默认当前时间
print(time.asctime()) # Sat Oct 12 18:41:56 2024
# 格式化时间,返回以可读字符串表示的当地时间,格式由参数 format 决定,默认当前时间戳
print(time.strftime('%Y-%m-%d_%H:%M:%S',time.localtime())) # 2024-10-12_18:41:56
# 指定时间戳,进行格式化
t = 1728729714.0869093
print(time.strftime('%Y-%m-%d_%H:%M:%S',time.localtime(t))) # 2024-10-12_18:41:54
pyinstaller:打包
打包时建议新建一个虚拟环境,安装好必要的依赖后,再打包,防止打包后的文件过大
安装:pip install pyinstaller
常用参数
- -F:生成一个可执行文件
- -i:该参数后跟可执行文件的icon图标路径
- -w:运行exe时,不显示命令行窗口(仅对Windows有效)
# 打包单个文件
pyinstaller your_script.py
# 打包多个py文件
pyinstaller [主文件] -p [其他文件1] -p [其他文件2]
# 打包时去除cmd框
pyinstaller -F -w XXX.py
# 打包加入exe图标 picturename.ico是图片
pyinstaller -F -i picturename.ico -w XXX.py